Deploy Ollama on Local Kubernetes in 15 minutes
Let’s deploy Ollama(LLM REST API) to your local Kubernetes
Overview
- Background
- Tools
- Install MicroK8s
- Add Kubernetes Resource from Dashboard
- Check the Dashboard
- Run Port Forward
- Test if it works!
- Conclusion
- Source
Background
Scalability and High Availability of your services are crucial in business and real-world scenarios. Kubernetes is the tool of this era to orchestrate this task. Imagine if you could deploy LLM as a REST API(with multiple models to choose from) and it is ready to scale.
Sounds too good to be true, eh?
Well, enter Ollama + Kubernetes.
Tools
We are going to demonstrate this combination of tools on your local MacOS. If you are using Linux and Windows, both tools are supported please check the official documentation.
MicroK8s — This tool allows you to run Kubernetes locally. I prefer this over Minikube because it’s lightweight, easy to install, and good for quick and easy experiments. It also comes with a Dashboard which we will use today. The dashboard is going to help you operate Kubernetes locally with its Web UI.
Ollama — This is a great tool for experimenting with and using the Large Language Model(LLM) as a REST API without scientists or extensive AI coding knowledge. Also, the list of models that can be used in Ollama is ever-growing(Gemma, Mistral, Orca, LLama2 and many more). Check the its library here.
With LLM as a REST API, you can imagine, you’d scale it like any other service on Kubernetes.
Ollama itself is optional because we will pull its image inside the Kubernetes anyway. It is nice to have because you can test our Kubernetes service with Ollama CLI.
Let’s get cooking.
Install MicroK8s
Run this series of commands in your terminal
Check out https://microk8s.io/docs/install-macos
or use a consolidated list here
#Download
brew install ubuntu/microk8s/microk8s
#Run installer
microk8s install
#Check the status while Kubernetes starts
microk8s status --wait-ready
#Turn on Dashboard service
microk8s enable dashboard
#Start using Kubernet
microk8s kubectl get all --all-namespaces
#Start using Dashboard
microk8s dashboard-proxy
#Utility command
#To Start and Stop
microk8s start
microk8s stopAfter running microk8s dashboard-proxy
you should see the URL and token needed to go into the dashboard.

Open the URL in a browser and should see the Dashboard. We are ready to add Kubernetes resources.
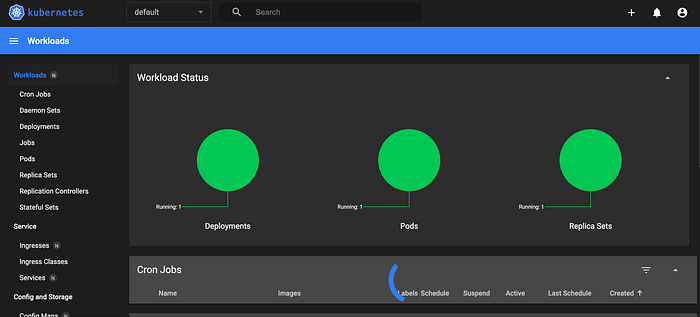
Add Kubernetes Resource from Dashboard
Click the + plus sign on the top right of the screen, you should see a form to add Kubernetes Resource

Add the following Namespace resource
Namespace
apiVersion: v1
kind: Namespace
metadata:
name: ollamaThen select this ollama namespace on the top left beside the Kubernetes logo

Let’s continue adding Deployment and Service resources in the aforementioned form.
Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama
namespace: ollama
spec:
selector:
matchLabels:
name: ollama
template:
metadata:
labels:
name: ollama
spec:
containers:
- name: ollama
image: ollama/ollama:latest
ports:
- name: http
containerPort: 11434
protocol: TCPService
apiVersion: v1
kind: Service
metadata:
name: ollama
namespace: ollama
spec:
type: ClusterIP
selector:
name: ollama
ports:
- port: 80
name: http
targetPort: http
protocol: TCPCheck the Dashboard
You should see Deployment and Service running in the dashboard


Run Port Forward
Wait until ollama deployment and service are green then run
microk8s kubectl -n ollama port-forward service/ollama 11434:80This will forward any localhost:11434 request to service port 80.
localhost:11434 is the Ollama standard address and port.
Test if it works!
Make sure the Ollama app is closed and any ollama serve is terminated on your local. Only microK8s should be running ollama. Then run this
ollama run orca-mini:3bor with CURL
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"Why is the sky blue?"
}'The first time you run this, it will take some time to pull the model. Go to the dashboard again and watch the pod log by clicking
Pods

click ollama-[hash key]
and click

You should see the log like this
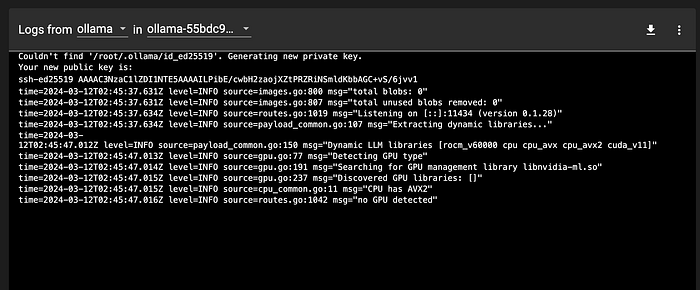
You should see either ollama CLI or curl return something after the model is loaded. Start Chatting!
Conclusion
Now you have the proof of concept of LLM REST API that’s open source and ready to scale into your enterprise Kubernetes Cluster.